
技术优势
· 全扫描模式:数据非依赖性采集模式,大大减少高丰度干扰,全面采集高低丰度信号,数据覆盖度提高近40%;
· 超高重现性、稳定性:大样本鉴定重复率提升近40%,定量精密度提升近1倍;
· 超高定量准确度∶定量能力接近金标准SRM /MRM靶向技术。
· 数据分析
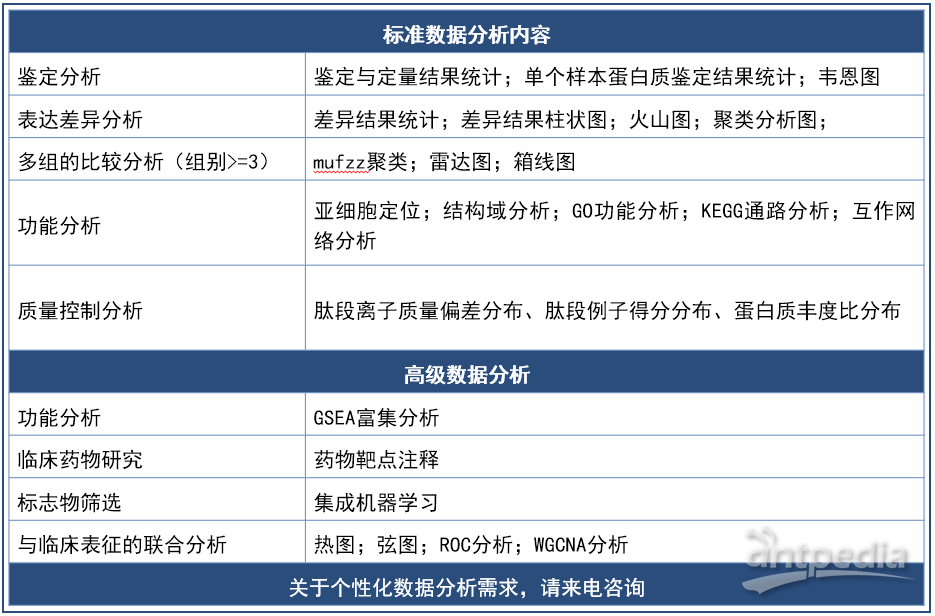
部分数据分析结果展示

· 推荐组合产品
1. 临床大队列研究“黄金”联合:DIA蛋白质组+DIA磷酸化蛋白质组
2. 标志物研究“一站式”解决方案:DIA蛋白质组+PRM
· 推荐应用领域
1. 临床疾病标志物筛选
2. 肿瘤疾病分子分型
3. 作物发育与品系比较
产品定义
DIA(Data Independent Acquisition)蛋白质组学属于非标记蛋白质组学方法,克服了传统蛋白质组学丰度依赖的缺陷以及低重复性、高随机性等难题,大大提高了蛋白质检测结果的重复性及稳定性。主要通过样本独立检测,采用质谱全扫描的方式进行全覆盖,并采用特异性二级碎片的强度进行大规模蛋白质定性和定量分析。
· 技术路线

备注:DIA与常规定量蛋白质组的最大不同之处在于“谱图库(spectral library)构建”,即DIA在进行样本检测之前,建议先进行建库操作。质谱对蛋白质肽段的鉴定,基于一级信号和二级图谱:在常规蛋白质组的扫描模式下,1张二级图谱几乎仅来自于1个一级信号;而在DIA全扫描模式下,1张二级图谱是一个混合图谱,来自于多个一级信号。通过建库方式进行精确匹配,可提高鉴定准确性,降低匹配难度。







