
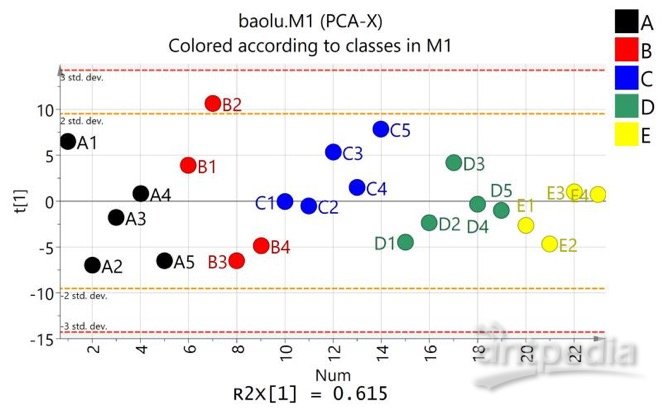
对样本进行主成分分析能从总体上反应各组样本之间的总体代谢差异和组内样本之间的变异度大小。使用SIMCA软件(V14.1, Umetrics, Umea, Sweden)对数据进行UV格式化(Unit Variance Scaling)和平均中心化(Mean-Centered)处理,然后进行自动建模分析,以获得更加可靠且更加直观的结果。例图如下所示:
为了消除与分类不相关的噪音信息,同时也为了获得导致两组之间显著差异的相关代谢物信息,我们采用正交偏最小二乘方判别分析(OPLS-DA)过滤与模型分类不相关信号即正交信号,获得OPLS-DA模型。对模型的质量用交叉验证法进行检验,并用交叉验证后得到的R2X 和Q2(分别代表模型可解释的变量和模型的可预测度)对模型有效性进行评判。在此之后,通过排列实验对模型有效性做进一步的检验。
例图如下所示:
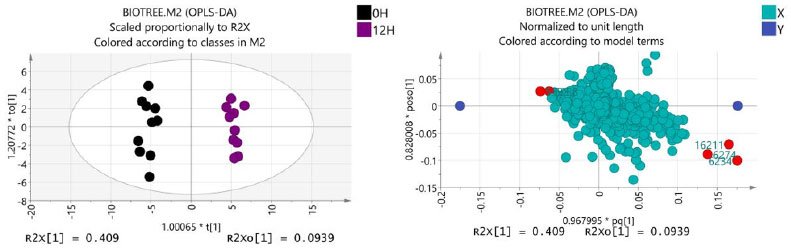
载荷图(loading plot)的横坐标代表每个物质在第一主成分上的载荷大小(cosα),纵坐标代表每个物质在第二主成分上的载荷大小(cosβ)
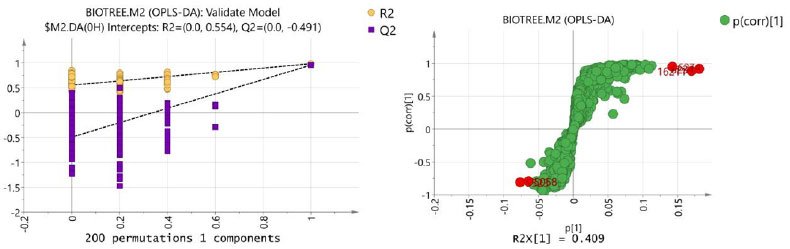
置换检验的横坐标代表随机分组的Y与原始分组Y的相关性,纵坐标代表R2和Q2的得分。
S-plot的横坐标代表每个物质在第一主成分上的载荷大小(cosα),纵坐标代表每个物质和第一主成分相关系数(可靠性)的大小。
ADDIN EN.REFLIST 1. XueKe G, Shuai Z, JunYu L, LiMin L, LiJuan Z, JinJie C. Lipidomics and RNA-Seq Study of Lipid Regulation in Aphis gossypii parasitized by Lysiphlebia japonica. Sci Rep 2017; 7(1): 1364.





