能够进行数据推理的第二代TPU
第一代的TPU只能用于深度学习的第一阶段,而新版则能让神经网络对数据做出推论。谷歌大脑研究团队主管Jeff Dean表示:“我预计我们将更多的使用这些TPU来进行人工智能培训,让我们的实验周期变得更加快速。”
“在设计第一代TPU产品的时候,我们已经建立了一个相对完善和出色的研发团队进行芯片的设计研发,这些研发人员也基本上都参与到了第二代TPU的研发工程中去。从研发的角度来看,第二代TPU相对于第一代来说,主要是从整体系统的角度,提升单芯片的性能,这比从无到有的设计第一代TPU芯片来说要简单许多。所以我们才能有更多的精力去思考如何提升芯片的性能,如何将芯片更好的整合到系统中去,使芯片发挥更大的作用。”Dean在演讲中表示。
未来,我们将继续跟进谷歌的进度,以进一步了解这一网络架构。但是在此之前,我们应当了解新一代TPU的架构、性能以及工作方式,明白TPU是如何进行超高性能计算的。在此次发布会上,谷歌并没有展示新一代TPU的芯片样片或者是更加详细的技术规格,但是我们依旧能够从目前所知的信息中对新一代TPU做出一些推测。

从此次公布的TPU图片来看,第二代TPU看上去有点像Cray XT或者是XC开发板。从图片上,我们不难发现,相互连接的几个芯片被焊接到了开发板上,同时保持了芯片之间以及芯片与外部的连接功能。整个板子上共有四个TPU芯片,正如我们之前所说,每一个单独的芯片都可以达到180TFLOPs的浮点性能。
在开发板的左右两侧各有四个对外的接口,但是在板子的左侧额外增加了两个接口,这一形式使得整个板子看上去略显突兀。如果未来每一个TPU芯片都能够直接连接到存储器上,就如同AMD即将推出的“Vega”处理器可以直接连接GPU一样,这一布局就显得非常有趣。左侧多出的这两个接口在未来可以允许TPU芯片直接连接存储器,或者是直接连接到上行的高速网络上以进行更加复杂的运算。
以上这些都是我们基于图片的猜测,除非谷歌能够透露更多的芯片信息。每一个TPU芯片都有两个接口可以与外部的设备进行连接,左侧有两个额外的接口对外开发,可以允许开发者在此基础上设计更多的功能,添加更多的扩展,无论是连接本地存储设备还是连接网络,这些功能在理论上都是可行的。(实现这些功能,谷歌只需要在这些接口之间建立相对松散可行的内存共享协议即可。)
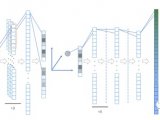
下图展示了多个TPU板一种可能的连接形式,谷歌表示,这一模型可以实现高达11.5千万亿次的机器学习计算能力。

这一结果是如何得出的呢。上面这种连接方式,从外形上来看,非常像开放的计算机架构,或者是其他的一些东西。纵向上来看,叠加了8个TPU板,横向上看,并列了4个TPU板。目前我们无法断定每一个开发板都是完整的TPU板或者是半个开发板,我们只能看到板子的一侧有6个接口,另一侧有2个接口。
值得注意的是,板子的中间采用了4个接口,而左右两侧采用了2个接口,并且在左右两侧也没有见到与TPU开发板类似的外壳。对此,一个比较合理的解释就是,左右两侧连接的是本地存储器接口,而不是TPU芯片接口。
即便如此,我们依旧能看到至少32个TPU二代母板在运行,这也意味着,有128个TPU芯片在同时运行。经过粗略的计算,整套系统的计算能力大概在11.5千万亿次。
举个例子来说,如果这一运算能力在未来能够运用到商业领域,谷歌现在进行的大规模翻译工作所采用的32个目前最先进的GPU,在未来就可以缩减为4个TPU板,并能够极大的缩减翻译所需要的时间。
值得注意的是,上文所提到的TPU芯片不仅仅适用于浮点运算,也同样适用于高性能计算。
TPU的训练与学习
与第一代TPU相比,第二代TPU除了提高了计算能力之外,增加的最大的功能就是数据推理能力,不过这一推理模型必须先在GPU上进行训练才可以。这一训练模式使得谷歌等开发厂商必须降低实验的速度,重塑训练模型,这将耗费更长的时间,才能使机器获得一定的数据推理能力。
正是因为如此,在相对简单和单一的设备上先进行训练,然后将结果带入带更为复杂的环境中去,从而获得更高层次的数据推理能力,这一迭代工程是必不可少的。未来,英特尔推出的用于人工智能的GPU也将会采用这一迭代模式。英伟达的Volta GPU也是如此。
拥有“tensor core”的英伟达Volta GPU拥有超高速的机器学习与训练能力,未来可能达到120万亿次的单设备计算能力,这一运算能力与去年上市的Pascal GPU相比,在计算能力上提升了大约40%。但是像谷歌推出的TPU这种超高速的计算能力所带来的影响,我们即便很难在生活中切身的体会到,但是GPU越来越快的计算能力依旧令人印象深刻,也离我们更近。
Dean表示,英伟达Volta所采用的架构是非常有趣的,这一架构使得通过核心矩阵来加速应用的目的成为可能。从一定程度上来说,谷歌推出的第一代TPU也采用了类似的想法,实际上,这些技术现在依然在机器学习的流程中被采用。“能够加快线性计算能力总是非常有用的。”Dean强调。
姑且不考虑硬件方面的影响,依然存在着许多能够吸引用户的地方。与那些始终保持机密的项目不同,未来,谷歌将会将TPU技术运用到谷歌云平台。谷歌的高级研究员Jeff Dean表示,他们不希望通过各种手段来限制竞争,希望能够为TPU提供更多的可能与空间,这样在未来才能够与Volta GPU以及Skylake Xeons竞争。

Dean认为,平台也应当为开发者提供更多能够建立和执行各自特有模型的机会,而不是限制开发者的思维。未来,谷歌将会在云平台上为那些对开放的科研项目感兴趣并不断推进机器学习的研究团队提供超过1000个TPU。
Dean表示,现在在谷歌内部,在进行机器训练和学习的时候,也会同时采用GPU和CPU,在同一设备上也是如此,这样能够更好的保证平衡。但是对于新一代的TPU芯片,目前来说,训练和学习时候的功率还不能够准确的估计,但是值得肯定的是,功能肯定是低于Volta GPU。由于系统在功能上能够满足高性能计算和64位高性能计算,这就使得工作负载的计算异常复杂。英伟达的GPU在使用过程中也会遇到类似的问题。未来,想要更好的解决这一问题,需要我们跟工程师继续努力。
在这一点上,Dean也承认:“与第一代TPU芯片整数计算的方式不同,第二代芯片能够进行浮点运算。所以在芯片进行学习训练的过程中,只需要采用固定的模型即可,不需要变动算法。工程师可以采用相同的浮点运算方式,这在很大程度上降低了工作量。”
除了英伟达和英特尔之外,谷歌将其定制的硬件产品推向市场,对于企业来说未尝不是一件好事。因为TPU来说对于市场来说还是相当边缘化的技术。当第二代TPU产品应用到谷歌云平台之后,谷歌将会向大量的用户推送培训,这将会更好的推动这一技术的发展。
对于哪些对于谷歌为什么不将芯片进行商业化的人来说,以上的内容大概能够给出一个回答。随着人工智能和神经学习技术的不断发展,TPU将能够在谷歌云上大展拳脚,成为推动技术进步的一大力量。












 首页
首页


