蛋白质组学的诞生和发展,离不开多学科和技术的逐渐交叉融合。这些学科技术包括(但不限于)基因组学、生物化学、分析化学、自动化、基于电磁场的精密质谱仪、信号处理、数理统计和计算机科学。近年来,分子医学、大数据技术和人工智能的发展,进一步加速推动了蛋白质组学的成长,使之在精准医疗领域展示出越来越大的应用潜力。

01蛋白质组学的华丽诞生
1994年,当27岁的博士研究生马克·威尔金斯(Marc Wilkins)在地广人稀的澳大利亚尝试把蛋白质(protein)和基因组(genome)拼成一个新的英语单词蛋白质组(proteome),用以描述基因组编码的所有蛋白质,并将这一单词放在他的博士毕业论文中时,他不会想到,3年后,瑞士苏黎世联邦理工大学的皮特·詹姆斯(Peter James)在他发表于剑桥大学《生物物理学》季刊的一篇53页的长文中借用了这个概念,并首次提出蛋白质组学(proteomics)一词,系统总结了当时已发表的对生物体内所有蛋白质种类的研究以及该类研究的进展。

蛋白质组学不是凭空诞生的一个新学科,而是基于一系列蛋白质的生物化学研究和多肽质谱的研究衍生发展而来的,所有这些相关学科的研究都被串起来,成为这一新学科的基石。
威尔金斯更不会想到蛋白质组学会受到如此广泛的关注。1997年,人类基因组计划进行得如火如荼,2001年,《科学》(Science)杂志和《自然》(Nature)杂志分别出版专刊,报道了人类基因组计划草图的完成,兴奋地宣告解读了人类生命的编码。
生命科学的中心法则清楚地表明,基因只是遗传编码,在生命活动中真正发挥作用的主要是蛋白质。
因此,在《科学》杂志报道人类基因组计划完成的专刊上,华盛顿大学的斯坦利·菲尔茨(Stanley Fields)预言蛋白质组学将很快取代基因组学成为生命科学研究的焦点;
《自然》杂志的专刊则在显著版面报道了人类蛋白质组学组织(HUPO)的成立,并宣告生命科学正式进入蛋白质组学时代。因为人类基因组计划的巨大成功,蛋白质组学在诞生之初,光环熠熠,世界各国对蛋白质组学予以大量投入,工业界也热情洋溢,不可谓不华丽。
现在,回顾蛋白质组学的华丽诞生,我们感情复杂。一方面,基因组学的巨大成功让全世界认识到蛋白质组学毋庸置疑的重要性;另一方面,蛋白质组学直到今天也还没有完全摆脱基因组学的巨大成功映射出的阴影带来的困扰。例如,在相当长一段时间内(直到今天仍然存在),蛋白质组学的别名是“功能基因组学”,因而其常常被列为基因组学的一部分而存在。
02基因组学巨大成功背后的阴影
人类基因组计划是将基因按照染色体的分布承包给各个研究团队,协同开发技术,分别测序,然后拼装成全基因组。这个化整为零、逐个击破的简单思路取得的成功,是迄今为止全世界不同国家的科学家互相协作、进行超大项目研究的成功典范。
早期参与人类蛋白质组计划的研究人员萧规曹随,选择了同样的思路,将蛋白质组按照染色体分组,然后分配给世界各国的参与团队。
后来的数据表明,这个复制和迎合基因组学的思路在蛋白质组学领域并未获得同行的一致认可,也没有取得其他生命科学领域的认可。
基于染色体的蛋白质组研究确实取得了不少成果,但与巨大的资金和热情投入而急速鼓吹起来的期望值相比,这些成果微小得几乎不能被人们看到。这一段至今尚未完全结束的历程,极大地消费了人们对蛋白质组学的期望和热情。
蛋白质组学的华丽诞生在其第一个10年感受到了全球各界的热情,出现了一段时间繁荣的景象:学术界和工业界的大量投入,专业杂志接二连三地涌现,影响因子逐年升高。今天,当我们拥有了高精度质谱仪和比较完善的算法后,回顾历史,我们不得不汗颜地承认:当时很多蛋白质组学研究所产生的数据信息量是非常低的,有些甚至是经不起时间考验的。
2014年,《自然》杂志仓促地发表了两篇号称是完成了人类蛋白质组草图的论文,认为其代表了当时蛋白质组学的最好研究。这两项研究在若干种不同人缘样本中对超过17000个蛋白质进行了鉴定,给观望蛋白质组学的大众打了两针兴奋剂。
但是后来,蛋白质组研究领域的多位同行对这两篇论文中所使用的数据分析方法提出了质疑,并证明其中有些数据是错误的,从而引发了大量的后续讨论。事实上,仅仅在多种样本中鉴定到这些蛋白质的表达,而不对它们进行精确的定量,并不会产生太大的生物学价值。
换言之,仅仅让大家看到蛋白质组学在经过17年的努力后终于在蛋白质鉴定水平达到了基因组测序覆盖率的70%(暂不考虑多肽水平的覆盖率),勉强及格,只是进一步加深了大家对“蛋白质组学从属于基因组学”这一误区的认同而已。
03蛋白质组学的牛刀小试
鉴于蛋白质的复杂性和多变性,完全意义上的蛋白质组学至今仍是一个科学目标或者科学理想,因为至今无人知道一个生物体内到底有多少蛋白质。比蛋白质组学本身更加繁荣的,并令所有人毫无争议的、振奋的乃是色谱-质谱方法学的巨大进展。
色谱-质谱技术在过去的20年高速发展,越来越多的生物医学科学家的研究受益于色谱-质谱技术的发展,比如未知蛋白质的鉴定、蛋白质相互作用的鉴定、翻译后修饰的鉴定、蛋白质结构的解析、靶向蛋白质定量、蛋白质降解的研究等。有些方法比如靶向蛋白质组学,正在走向临床试验。但是严格意义上讲,这些都不是蛋白质组学的主要内涵。令人尴尬的是,虽然色谱-质谱技术取得了长足的进步,但蛋白质组学这一学科却逐渐淡出主流研究的视野。
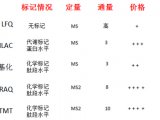
蛋白质组学不是没有获得过大众认可的成功。比如,基于同位素标记的定量蛋白质组学可以对2~4个样本的蛋白质组进行准确定量,在进行良好的实验设计和实施后,8000个以上的蛋白质(基因产物)可以被鉴定到,并且含有准确的定量信息,进而引导新的生物学发现。虽然这些成功往往只出现在一部分拥有高超实验技巧的蛋白质组学实验室,但这已经可以让大众慢慢意识到蛋白质组学在生物研究中实实在在的强大力量,从而获得了一部分支持。实际上,跟蛋白质组学博大的内涵相比,这些成功只能算是牛刀小试。
04蛋白质组学和精准医疗
人类的几乎所有生命活动都是由人体内的蛋白质执行的。人类的健康和疾病同蛋白质息息相关,而疾病治疗的效果也取决于蛋白质机器的调控。所有熟悉生物学中心法则的大众应该没有人会质疑蛋白质在精准医疗中不可替代的作用。
蛋白质组学作为研究所有蛋白质的科学,毫无疑问将在精准医疗领域发挥最关键的作用。然而,直到最近,这些作用还只能被称为“潜力”。
蛋白质组学发展到今天,才刚刚走过21个年头。被撇在基因组巨大的身形背后,21岁的蛋白质组学常常有意无意被人遗忘,或者被认为是可有可无的“跟班”或“锦上之花”。生物学的中心法则在基因组的灿烂光环下黯然失色。
基因组学在种类众多但数量有限的遗传性单基因疾病和产前诊断中展示了毫无争议的作用后,一般被大众误解为精准医疗的主要甚至是唯一的方式。
笔者认为,对基因组学与其实际生物学功能不相称的期望,为今后基因组学在数量更多的人类复杂疾病(比如绝大部分肿瘤、代谢性疾病、心脑系统疾病等)中的临床应用的跌宕,埋下了伏笔。
近年来,越来越多的科学家开始重新思考蛋白质组学在精准医疗中的应用,并且一系列切实的蛋白质组项目正在开展。
虽然年轻的蛋白质组学已经经历了一系列盛衰荣辱,但其成长在跌宕起伏中一刻也未停止过,尤其是近5年来,已在各个技术环节取得了突破性的进展。
现在,我们已经有新技术可以对极小量的临床样本进行高通量的、快速、准确的蛋白质组学水平的定量,并且在越来越多的临床应用中展示出独特的、有效的作用,主流生命科学界和医学界的关注与日俱增,其他领域比如医疗大数据和人工智能的研究人员也展示出了极大的兴趣。
蛋白质组(Proteome)的概念最先由Marc Wilkins提出,指由一个基因组(Genome),或一个细胞、组织表达的所有蛋白质(protein). 蛋白质组的概念与基因组的概念有许多差别,它随着组织、甚至环境状态的不同而改变。 在转录时,一个基因可以多种mRNA形式剪接,一个蛋白质组不是一个基因组的直接产物,蛋白质组中蛋白质的数目有时可以超过基因组的数目。 蛋白质组学(Proteomics)处于早期“发育”状态,这个领域的专家否认它是单纯的方法学,就像基因组学一样,不是一个封闭的、概念化的稳定的知识体系,而是一个领域。
主要功能
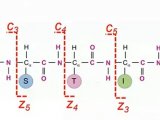
蛋白质组学集中于动态描述基因调节,对基因表达的蛋白质水平进行定量的测定,鉴定疾病、药物对生命过程的影响,以及解释基因表达调控的机制. 作为一门科学,蛋白质组研究并非从零开始,它是已有20多年历史的蛋白质(多肽)谱和基因产物图谱技术的一种延伸. 多肽图谱依靠双向电泳(Two-dimensional gel electrophoresis, 2-DE)和进一步的图象分析;而基因产物图谱依靠多种分离后的分析,如质谱技术、氨基酸组分分析等.
由于可变剪辑及RNA编辑的存在,许多基因可以表达出多种不同的蛋白质。因此,蛋白质组的复杂度要比基因组的复杂度高得多。
如果某物种的基因组全序列已经破译,并不代表该物种的蛋白质组也已破译。 具体分析某个基因的蛋白质产物要综合基因组水平、转录水平和翻译水平的修饰及调控来确定。
研究内容
主要有两方面,一是结构蛋白质组学,二是功能蛋白质组学。其研究前沿大致分为三个方面:
① 针对有关基因组或转录组数据库的生物体或组织细胞,建立其蛋白质组或亚蛋白质组及其蛋白质组连锁群,即组成性蛋白质组学。
② 以重要生命过程或人类重大疾病为对象,进行重要生理病理体系或过程的局部蛋白质组或比较蛋白质组学。
③ 通过多种先进技术研究蛋白质之间的相互作用,绘制某个体系的蛋白,即相互作用蛋白质组学,又称为“细胞图谱”蛋白质组学。
此外,随着蛋白质组学研究的深入,又出现了一些新的研究方向,如亚细胞蛋白质组学、定量蛋白质组学等。蛋白质组学是系统生物学的重要研究方法.
技术原理
双向凝胶电泳技术(2-DE)
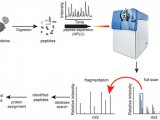
双向凝胶电泳技术与质谱技术是目前应用最为广泛的研究蛋白质组学的方法。双向凝胶电泳技术利用蛋白质的等电点和分子量差别将各种蛋白质区分开来。虽然二维凝胶电泳难以辨别低丰度蛋白,对操作要求也较高,但其通量高、分辨率和重复性好以及可与质谱联用的特点,使其成为目前最流行、可靠的蛋白质组研究手段。双向凝胶电泳技术及质谱基础的蛋白质组学研究程序为样品制备→等电聚焦→聚丙烯酰胺凝胶电泳→凝胶染色→挖取感兴趣的蛋白质点→胶内酶切→质谱分析确定肽指纹图谱或部分氨基酸序列→利用数据库确定蛋白。蛋白质组研究要求有高分辨率的蛋白质分离及准确、灵敏的质谱鉴定技术。凝胶电泳中蛋白质的着色不仅影响蛋白质分离的分辨率,同时也影响后续的质谱鉴定。蛋白质的染色可分为有机试剂染色、银染、荧光染色及同位素显色四类。
Unlu 等提出了一种荧光差异显示双向电泳(F-2D-DIGE)的定量蛋白质组学分析方法。差异凝胶电泳(DIGE)是对2-DE 在技术上的改进,结合了多重荧光分析的方法,在同一块胶上共同分离多个分别由不同荧光标记的样品,并第一次引入了内标的概念。两种样品中的蛋白质采用不同的荧光标记后混合,进行2-DE,用来检测蛋白质在两种样品中表达情况,极大地提高了结果的准确性、可靠性和可重复性。在DIGE技术中,每个蛋白点都有它自己的内标,并且软件可全自动根据每个蛋白点的内标对其表达量进行校准,保证所检测到的蛋白丰度变化是真实的。DIGE 技术已经在各种样品中得到应用。
高效液相色谱技术(HPLC)
尽管二维凝胶电泳(2-DE)是常用的对全蛋白组的分析方法,但其存在分离能力有限、存在歧视效应、操作程序复杂等缺陷。对于分析动态范围大、低丰度以及疏水性蛋白质的研究往往很难得到满意的结果。Chong 等使用HPLC/ 质谱比较分析恶性肿瘤前和癌症两种蛋白质差异表达。利用HPLC 分离蛋白质,并用MALDI-TOF-MS鉴定收集的组分,从而在两种细胞中的差异表达中对蛋白质进行定量分析。多维液相色谱作为一种新型分离技术,不存在相对分子质量和等电点的限制,通过不同模式的组合,消除了二维凝胶电泳的歧视效应,具有峰容量高、便于自动化等特点。二维离子交换-反相色谱(2D-IEC-RPLC)是蛋白质组学研究中最常用的多维液相色谱分离系统。
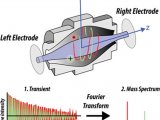
质谱技术
最早是MALDI-TOF,MALDI基质辅助激光解吸离子化技术于2002 年由诺贝尔化学奖得主田中发明,刚刚产生便引起学术界的高度重视。MALDI和TOF(飞行时间质谱)搭配是一个理想的快速鉴定技术。最早,SELDI 技术是蛋白质组学研究中比较理想的技术平台,其全称是表面增强激光解吸电离飞行时间质谱技术(SELDI-tof)。其方法主要如下:通常情况下将样品经过简单的预处理后直接滴加到表面经过特殊修饰的芯片上,既可比较两个样品之间的差异蛋白,也可获得样品的蛋白质总览。因此,在应用方面具有显著优势。SELDI 技术分析的样品不需用液相色谱或气相色谱预先纯化,因此可用于分析复杂的生物样品。SELDI 技术可以分析疏水性蛋白质,PI 过高或过低的蛋白质以及低分子质量的蛋白质( < 25 000) ,还可以发现在未经处理的样品中许多被掩盖的低浓度蛋白质,增加发现生物标志物的机会。SELDI 技术只需少量样品,在较短时间内就可以得到结果,且试验重复性好,适合临床诊断及大规模筛选与疾病相关的生物标志物,特别是它可直接检测不经处理的尿液、血液、脑脊液、关节腔滑液、支气管洗出液、细胞裂解液和各种分泌物等, 从而可检测到样品中目标蛋白质的分子量、PI、糖基化位点、磷酸化位点等参数。
后来,人们发现SELDI-TOF的数据并不是很理想,由于蛋白质组学的复杂性,SELDI-TOF号称的种种“发现肿瘤Pattern”等被证明是不可靠的。SELDI-TOF当时的过度宣传,和马上被证实的不可靠,被人们抛入了谷底,打入了冷宫。目前,人们认为如果采用MALDI技术,至少要接串联质谱。
在初期的高通量鉴定时代,第一个获胜的技术是MALDI-TOF/TOF,它和2D PAGE连接,实现了生物学家更容易理解的,跑胶-分离提取-质谱鉴定的流程。
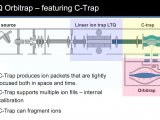
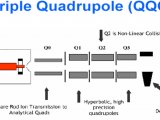
与此竞争的技术是2D HPLC-MS(这个MS可以是:LCQ、LTQ、Q-TOF、Orbitrap),这些也都是串联质谱技术。后来2D HPLC-MS技术逐步战胜了MALDI-TOF/TOF技术,因为跑胶,不能在线,也很难重现。当2D HPLC技术克服了重重难关后,越来越多的人放弃了MALDI-TOF/TOF技术。
在高通量鉴定时代之后,进入了更多的Biomarker发现,定量,磷酸化等翻译后修饰鉴定,蛋白-蛋白相互作用等时代。这时的精细鉴定,更需要LC-MS技术,MALDI-TOF/TOF技术就更被人们暂时抛到脑后。直到最近,人们步入到质谱成像阶段,越来越多的医学工作者更加容易信任成像技术,而MALDI成像相对于基于ESI的质谱,更容易实现稳定可靠的成像。
同位素标记亲和标签(ICAT)技术
同位素亲和标签技术是一种用于蛋白质分离分析技术,此技术是蛋白质组研究技术中的核心技术之一。该技术用具有不同质量的同位素亲和标签( ICATs) 标记处于不同状态下的细胞中的半胱氨酸,利用串联质谱技术,对混合的样品进行质谱分析。来自两个样品中的同一类蛋白质会形成易于辨识比较的两个不同的峰形,能非常准确的比较出两份样品蛋白质表达水平的不同。ICAT 的好处在于它可以对混合样品直接测试;能够快速定性和定量鉴定低丰度蛋白质,尤其是膜蛋白等疏水性蛋白等;还可以快速找出重要功能蛋白质。
由于采用了一种全新的ICAT试剂,同时结合了液相色谱和串联质谱,因此不但明显弥补了双向电泳技术的不足,同时还使高通量、自动化蛋白质组分析更趋简单、准确和快速,代表着蛋白质组分析技术的主要发展方向。针对磷酸化蛋白分析以及与固相技术相结合ICAT技术本身又取得了许多有意义的进展,已形成ICA T 系列技术。
生物信息学技术
生物信息学在生命科学研究中起着越来越重要的作用。利用生物信息学对蛋白质组的各种数据进行处理和分析,也是蛋白质组研究的重要内容。生物信息学是蛋白质组学研究中不可缺少的一部分。生物信息学的发展,已不仅是单纯的对基因组、蛋白质组数据的分析,而且可以对已知的或新的基因产物进行全面分析。在蛋白质组数据库中储存了有机体、组织或细胞所表达的全部蛋白质信息,通过用鼠标点击双向凝胶电泳图谱上的蛋白质点就可获得.
鉴定方法
如蛋白质鉴定结果、蛋白质的亚细胞定位、蛋白质在不同条件下的表达水平等信息。目前应用最普遍的数据库是NRDB和dbEST 数据库。NRDB由SWISS2PROT 和GENPETP 等几个数据库组成,dbEST是由美国国家生物技术信息中心(NCBI)和欧洲生物信息学研究所(EBI)共同编辑的核酸数据库;计算机分析软件主要有蛋白质双向电泳图谱分析软件、蛋白质鉴定软件、蛋白质结构和功能预测软件等。
研究进展
2014年5月28日,英国新一期《自然》杂志公布两组科研人员分别绘制的人类蛋白质组草图。这一成果有助于了解各个组织中存在何种蛋白质,这些蛋白质与哪些基因表达有关等,从而进一步揭开人体的奥秘。
上世纪90年代,人类基因组计划开始成形时,有科学家提出了破译人类蛋白质组的想法。其目标是将人体所有蛋白质归类并描绘出它们的特性、在细胞中所处的位置以及蛋白质之间的相互作用。但人类蛋白质组的规模和复杂性使此类研究困难重重。
研究人员借助计算机对这些蛋白质片段与基因组进行了大量比对工作,并据此列出一个“清单”,描绘出哪些组织中的哪些基因表达与蛋白质的形成有关。在另一项研究中,美国约翰斯·霍普金斯大学研究人员与印度等国同行也采用质谱分析法绘制出一张蛋白质组草图。

















































 首页
首页


