引言
数据非依赖采集(Data-Independent Acquisition, DIA)是当前最热门的质谱采集技术之一,它以非目标的方式将质量范围分为若干窗口,依次并循环采集窗口内所有母离子的二级碎片[1,2]。DIA 与 SRM 类似,也是基于子离子(transition)定量,相比传统蛋白质组学定量方法具有更好的选择性和更高的准确度。然而,目前DIA在翻译后修饰分析上仍有较大瓶颈。DIA 依赖于 DDA 建立谱图库,而 DDA 数据在搜库鉴定时,修饰位点定位错误的概率较高,特别是磷酸化修饰发生在常见的 S/T/Y 上,若肽段含有 2 个或以上位置接近的 S/T/Y,位点就容易找错。将含有错误位点信息的鉴定结果作为谱图库,就会导致翻译后修饰 DIA 解析结果的不可靠[3]。因此,DIA 尚难用于大规模的翻译后修饰样本分析。
针对修饰位点的打分算法使修饰位点的定位更加准确,Proteome Discoverer 软件中整合的 phosphoRS/ptmRS 模块[4]和 MaxQuant 软件的算法[5]都可以实现位点可信度(Site Probability)的计算,从而获得可靠的位点定位信息。本文基于上述软件对翻译后修饰 DDA 数据进行位点可信度分析,筛选具有准确位点定位的谱图建立谱图库,导入 Skyline 软件,进而实现可靠的翻译后修饰 DIA 解析。将该流程应用于磷酸化样本 DIA 数据分析,成功提取 6401 条高可信度的磷酸化肽段(Q < 0.01),占谱图库肽段总数的 98.4%,其中可用于准确定量的肽段(CV < 20%)占 86.9%,有效解决了翻译后修饰 DIA 定量的难题。
实验条件
实验材料和方法
来源于大鼠组织富集的磷酸化样本,最终上样量为 700 ng/run,分别进行 DDA 和 DIA 采集,每种采集模式重复 3 遍。
色谱条件
纳流高效液相色谱仪:EASY-nLC 1000(Thermo Scientific)
分析柱:纳流 C18 色谱柱(长15cm, ID 75 μm, 粒径3 μm)
流动相:A:0.1% 甲酸水溶液;B:0.1% 甲酸乙腈溶液
梯度:0–3 min, 3–7% B; 3–95 min, 7–22% B; 95–113 min, 22–35% B; 113–116 min, 35-90% B; 116-120 min, 90% B
流速:300 nL/min
质谱条件
质谱仪:Orbitrap Fusion(Thermo Scientific);
离子源:NanoFlex;离子模式:正离子;喷雾电压:1.8 kV;毛细管温度:275°C;S-Lens RF:60%
DDA:分辨率:一级120,000@m/z 200,二级30,000@m/z 200;AGC:一级2e5,二级5e4;二级Maximum Injection Time:100 ms;碰撞能量:HCD 30%
DIA:质量范围:m/z 400–1200;窗口:25 m/z(窗口间 1 m/z 重叠,实际 Isolation window 设 26 m/z);二级分辨率:30,000@m/z 200;二级AGC:1e5;二级 Maximum Injection Time:85 ms;碰撞能量:HCD 30%;每个 DIA 循环之间插入一次一级扫描。
数据处理
基于 Proteome Discoverer 2.0 软件进行 DDA 鉴定、位点筛选和谱图库建立,Proteome Discoverer 1.4 和 MaxQuant 也可以实现相同的工作。
搜库鉴定参数:Uniprot 大鼠蛋白数据库,母离子质量偏差:10 ppm;碎片离子质量偏差:0.02 Da;固定修饰:C 烷基化(+57.021 Da);动态修饰:M 氧化(M+15.995 Da);S/T/Y 磷酸化(S/T/Y+79.966 Da);酶:trypsin;Q 值(Percolator):< 0.01;ptmRS 模块:PhosphoRS mode: True; Use diagnostic ions: True
位点筛选和谱图库建立:对 PSM 表格“Isoform Confidence Probability”一项进行筛选,保留 _ 0.75 的结果,导成 PepXML 格式,并将相应谱图导成 mzML 格式。PepXML 文件和 mzML 文件同时导入 skyline 建立高可信磷酸化肽段谱图库。
DIA 数据 Skyline 解析:根据 DIA 采集参数设置隔离窗口,将谱图库中所有肽段及相应蛋白作为 Targets,每个肽段选取强度最高的 6 个 b/y 离子进行峰抽提,提峰结果使用 mProphet 进行假阳性评估,控制 Q 值 < 0.01。
实验结果
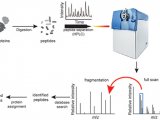
1. 精确修饰位点谱图库建立与 DIA 解析流程
由于肽段中含有多个可能发生翻译后修饰的位点,如果不对可能发生修饰的位点进行可信度打分,会造成翻译后修饰位点的错误匹配和定位。将错误匹配和定位的翻译后修饰肽段作为谱图库,就会导致 DIA 解析结果的错误。这是目前翻译后修饰 DIA 分析的瓶颈所在。
基于 Proteome Discoverer 的 phosphoRS/ptmRS 算法能够对可能发生修饰的位点进行打分(Site Probability),判断定位的准确性。通常认为 Probability _ 75(100 分制)或 0.75(1 分制)的位点定位准确、可靠;具有多个修饰位点的肽段,其所有位点的 Probability 均 _ 75(或 0.75),则修饰位点及 isoform 唯一确定。通过这一方法,筛选出位点准确可信、isoform 唯一确定的 PSM(即 Isoform Confidence Probability 75(或0.75)建立谱图库,实现精确的翻译后修饰 DIA 分析。整个流程如图 1 所示。

图 1. 精确修饰位点谱图库建立流程图













 首页
首页


