相比一维色谱,全二维色谱利用两根不同性质的色谱柱实现“正交分离”,极大增加了峰容量,可以一次性得到几千甚至上万种化合物信息,是针对复杂样品分析的强大工具。但大量的数据信息也造成了一些困扰,对于习惯了使用常规一维色谱分析的用户来说,初次见到全二维色谱的谱图,往往有种不知所措的感觉,看不懂谱图上都是什么,更不要提做分析数据了。现在,我们为大家介绍一下全二维色谱的数据处理基本流程,希望看完以后,大家不仅能看懂全二维色谱的谱图,还能知道怎样对其中大量的信息进行处理了。
其实,全二维色谱的数据处理过程和一维色谱基本一致,首先把数据转化成谱图;然后在谱图上对峰进行识别和积分,形成峰列表;接下来就可以进行常规的定性和定量工作了。
谱图显示
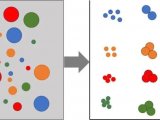
当做完了一次分析得到数据后,第一步是将数据显示成谱图。一维色谱很直接,把信号对时间作图就得到了一张色谱图。但在全二维色谱中,情况就有点不一样了。由于全二维分析是通过调制器将所有在一维色谱柱上的馏出物以一定的时间间隔(称为调制周期)进行收集,再快速进样到二维,相当于对一维馏出峰(可能是共馏出峰)做了很多次切割,切割出来的小部分再进行进一步分析。比如下面对一段含有红、黄、蓝三种物质的共馏出峰做切割。

这样检测器得到的最终数据其实是N次二维柱上的分析结果头尾相连的叠加,其中N等于总分析时间除以调制周期PM。如果按照一维谱图的方法显示,就会像上图一样,有很多物质的峰重复出现(因为一维馏出的同一个峰一般会被切割好几次送入二维柱),影响后续的分析。所以需要对原始数据做一次转换(Transformation),将每一个单独的二维柱数据结果转置90˚,形成了一个N×m的矩阵,其中m等于调制周期PM乘以采样频率。显示出的谱图就是一个三维立体图,为了方便后续分析计算,经常使用轮廓图或等高线图的形式来显示。横轴表示一维上的保留时间,纵轴表示二维上的保留时间,第三维的响应信号值或峰高就用不同颜色来表示。
由于同一个物质在二维柱上的出峰时间基本一致,可以通过这个条件将一维馏出的属于同一个物质的不同切片峰重新合并起来(如上图中同样颜色的不同切片),所以,在全二维谱图中,一个“峰(Peak)”其实是由很多个切片峰(Peaklet /Slice)组成的。为了美观效果,属于同一个峰的几个切片峰会通过软件算法进行平滑处理,看起来就像一个斑块,有些软件也把它称为“峰斑(Blob)”。
将响应信号值或峰高对应到具体的颜色可以选择不同的色标(Color Scale),从而产生不同颜色的二维图。一般选择背景信号(噪音)和最高信号为互补色或有强烈对比的颜色,这样谱图上信号比较容易识别。而最大和最小值之间包含越多颜色种类,则显示的层次也就越丰富。在信号值和颜色值对应方法上,有对数映射和线性映射两种方式,对数映射可显示更大范围的信号值,但对一些无效信号(如柱流失、溶剂拖尾或杂质物质等)也会同时反映在谱图上;线性映射则着重反映小范围的信号变化,谱图相对干净简洁,重点突出。另外,也可以通过改变谱图饱和度数值(最大颜色值代表的信号值)来调节颜色显示范围情况。

虽然理论上可以计算出一维柱馏出物进入二维柱的开始时间,然后从这个时间开始对原始数据进行转换生成二维矩阵,但一般没有必要这么做。因为在二维的分离上,主要关心的是物质之间的相对位置关系,所以二维分离开始时间的选择是任意的。实际上,在生成谱图后,用户可以通过调节二维偏移时间,按照由低到高的二维保留时间,得到一个尽量完整的谱图分布。
但是,有些情况,无论怎么调整二维偏移时间,都有一些物质无法在一个周期内显示出来。这说明二维分离所需的时间超过了调制周期,这种现象被称为“峰迂回(wrap-around)。假如迂回严重,前一个周期的物质和后一个周期的物质同时馏出到达检测器,产生了峰重叠和干扰,对后续数据分析造成不便。这需要通过改变全二维方法或色谱柱种类规格来改善。
现在绝大多数软件都支持将全二维谱图以三维形式呈现,用户可以改变三个方向上的角度对谱图进行全方位的观察,有助于直观的了解真实信号的大小。但这种图一般只用于结果展示,并不适合做进一步数据分析。
峰积分
有了上面的介绍,全二维谱图的峰积分就比较容易理解了。大多数全二维数据处理软件都先对原始一维谱图进行峰识别和积分,方法和常规一维色谱基本一样。在将同一个物质的切片峰合并后,一个峰包含了多个切片峰信息,包括切片数,每个切片峰的保留时间,峰高,峰面积等。二维峰的保留时间主要由最大切片峰(峰高最大的切片峰,也称为主切片峰)的保留时间确定;将所有切片峰峰面积相加就得到该峰的峰面积。还有一种算法是将切片峰组合而成的峰先拟合成一个三维的形状,通过计算这个三维峰的体积,得到所谓的“峰体积(peak volume)。
这样一来,问题的关键就在于应该遵循什么原则进行峰合并。之前已经提到过,同一个物质一维馏出的时候被切成很多片,但这些切片峰都集中于相邻几个周期内,前后相距时间不会太长,可以认为不同切片峰在二维进行分离时的温度基本一致(或者后面的切片经历的温度会略微高一点,如果柱箱设置为程序升温的话),所以他们在二维柱上馏出的时间就是纵轴数值应该基本一致。很多算法就是利用这一点,将相邻周期内二维馏出时间接近的峰识别成同一个物质的峰,并将其合并起来。当然除此之外,还需要其他的一些特征条件来认定。另外,如果是质谱数据,也可以将是否含有相同的碎片离子作为一个额外的筛选条件,提高识别准确率和可靠性。现代全二维色谱数据软件都具备自动峰识别、合并和积分计算的功能。
当所有峰的合并和积分计算完成后,就得到一个峰列表(Peak Table),包括识别成功的所有峰的信息,包括一维保留时间、二维保留时间、峰面积等。用户可在峰列表上选择任意一个峰,软件就会显示组成这个峰的所有切片峰的信息,同时该峰主切片所在周期内的原始数据也会显示出来,方便用户观察原始峰型和分离细节。如果是质谱数据,还可以看到离子图,以及和NIST图库的匹配结果等信息。

定性与定量
对于非质谱数据的定性,一般通过与标准物质的保留时间对比进行定性(目标物分析)。全二维色谱有两个保留时间数值,相当于每个物质对应于一个坐标,这样定性准确性相比常规一维有所提高。对于使用EI电离源(70eV)的质谱数据,可以直接调用NIST或其他质谱库进行匹配,自动得到峰列表中所用物质的匹配信息(未知物分析)。当然,对于自动匹配的结果,一般都需要根据保留指数或者其他化学信息,进行修正或选择。
建立了峰列表得到了所有峰的信息后,全二维数据的定量和常规一维定量方法就基本一致了。对于非质谱数据,一般用峰高或峰面积定量;对于质谱数据,可以用TIC也可以用EIC进行定量。值得一提的是,由于全二维色谱的正交分离特性,在全二维谱图上属于同一类物质的峰往往形成规律的分布,便于对复杂样品进行族类划分(Group Classification)。下面用一个例子来说明族类分析的原理和应用。
比如要测定一种原料油里面的饱和烷烃、单环芳香烃、双环芳香烃、三环芳香烃的相对比例。如果用常规一维做,先要用标样建立一个保留时间标准库,然后分析样品。先不说复杂样品能不能完全分离,即使用了长柱子花很长时间分离出来所有物质,根据标准库将所有峰定性完成,将所有的峰都归类到相应的化合物族,然后将同类物质合并计算。整个过程耗时耗力,准确性也不高。如果用全二维色谱分析样品,由于饱和烷烃和各种芳香烃不同的极性,在二维上这些属于不同族的化合物实现了分离,这样不同类别的化合物分布排列在不同空间区域内。用户可以手动方式建立一个包含所有同类化合物的封闭区域(可借助质谱定性结果确定区域边界),定义为一个区域型族。同一族内的所有峰可统一进行处理或加和。建立好所有族类后,自动得到各族之间的含量比例。该方法十分方便快捷,而且非常容易实现自动化,分析效率和分析准确性也大大提高。

除了区域型族,还可以自行选择几个特定的峰,组合成散点族。在目标物分析和定量(比如将标准物质定为一个族)方面有很多应用。
高级数据处理方法
全二维色谱由于其强大的分离能力,从一开始就被用于非同寻常的复杂样品分析,提取重要化学信息。比如分析用不同年份和产地出产葡萄酿的红酒中微量风味物质的差别来确定天气和环境因素对葡萄酒品质的影响;或者通过发现健康和患病人群中代谢产物变化确定标志物质来准确诊断等等。这些应用中都需要对大量谱图进行比较,寻找相同的特征,更要发现不同的差别。通常会用到统计分析、模式识别等高级功能,关于这些功能,我们以后有机会再给大家介绍。
*本文中所有实际全二维谱图均由雪景科技Canvas全二维色谱数据处理软件绘制。
**不同厂家全二维色谱数据软件中对应的名称略有差别,请参考各厂商软件说明书。
如需转载,请联系雪景科技全二维,并注明出处。
关注雪景科技全二维,如果您有任何要求或问题,请给我们留言哦!
详细信息请
www.jnxtec.com
400-1800--992






















 首页
首页
