前言:本文不是科研论文,也不是科学研究,仅仅是在工作中的经验总结,对文中引用的参数模型也没有做详细的探讨,欢迎对本文感兴趣的朋友可以随时和我一起探讨。
绘制标准曲线是生物学实验、临床检测、药物筛选过程中的一项重要步骤,获取准确可靠的实验数据是绘制标准曲线的前提。BioTek 的酶标仪、成像仪、洗板机、分液器等仪器设备为获得准确的数据提供了可靠的保障,Gen5软件提供了符合GxP标准的数据采集和数据分析步骤。本文以BioTek 的Gen5软件为例,介绍如何使用Gen5软件绘制理想的标准曲线。
文章不对复杂繁琐的数学公式进行解析,也不分析统计模型,仅仅对在使用Gen5软件绘制标准曲线过程中遇到的问题进行分析和讲解。本文从如何使用Gen5绘制标准曲线开始,阐述了如何设置、判断标准曲线的相关参数:R2值、加权因子、SSE、AIC 、WSS等参数,以及他们的意义。
下面以我们最常见的BCA蛋白检测为例,讲解一下如何使用Gen5绘制标准曲线。BCA蛋白浓度检测是一个实验室常见的实验,是根据吸光值可以推算出蛋白浓度。碱性条件下,蛋白将Cu2+还原为Cu+, Cu+与BCA试剂形成紫颜色的络合物,测定其在562nm处的吸收值,并与标准曲线对比,即可计算待测蛋白的浓度。
这里不阐述如何进行BCA实验的准备步骤,只讲解如何进行检测和数据分析。
第一步:设计合适的检测步骤,检测波长562nm
第二步:样品在微孔板的布局排列
我们设置了两个空白孔,5个浓度的标准品,每个标准品重复两次。每个样品也重复两次。

800TS 酶标仪即可完美胜任BCA的检测。
眨眼之间,仪器就把每个样品对应的OD562nm的吸收值检测完成。

由于我们设置了空白对照孔,在分析中,我们第一步就是要扣除空白对照的OD值,软件会自动进行空白扣除。

如果要得到我们待测样品蛋白浓度,就必须绘制一个标准曲线,Gen5支持多达几十种拟合类型的标准曲线,包括最基础最常用的线性拟合,也包括多项式,四参数(4-P),五参数(5-P)非线性拟合分析。多种拟合方式确保Gen5可以满足各种不同的实验需要。但是如何找到适合自己实验的标准曲线类型,也是让人头痛的问题。
在BCA实验中大家都知道,标准品中蛋白浓度和络合物的紫色颜色的深浅(OD562)成直线关系,可以使用下面的公式表达出来:Y=A*X+B,X代表自变量,一般是浓度等变量,Y代表因变量,一般是检测数值。A表示该公式直线对应的斜率,B是当X=0时,直线对应的截距。Gen5提供多种线性拟合方式:Y=A*X+B,Y=A*Log(X)+B,Log(Y)=A*X+B,Log(Y)=A*Log(X)+B,以满足不同实验的需要,下面举两个示例进行说明。
拟合类型的选择一般是步骤是:
先参考试剂或方法说明,按照试剂说明选择合适的拟合类型
如果自变量(X)和因变量(Y,仪器响应值)直接相关,一般选择线性拟合,如上面的BCA蛋白检测
如果自变量(X)和因变量(Y,仪器响应值)间接相关,一般选择对数线性拟合、多项拟合、4P拟合等。
试剂说明书如果没有指明拟合类型的曲线,先观察自变量和因变量之间的数据关系,先确定是线性还是非线性拟合
无论是线性拟合还是非线性拟合,都是先从简单的开始
如上面的BCA实验,浓度值和仪器响应值(OD值)直接相关,我们先做线性拟合,Y=A*X+B,得到下面的曲线。
曲线公式:Y=0.0143+0.00348X
R2=0.992
SSE=0.011
绘制标准曲线是否合适,如何评价呢?
第一个就是重复实验(或设置平行样品)是必需的,避免单次实验的随机性带来的误差。
第二个就是我们大家一直在使用R2值,R2值是评估一个曲线拟合程度好坏的一个重要指标,在实验中被广泛使用,一般我们认为R2值>0.9(or R2值>0.99)时,曲线拟合效果良好。R2值>0.9也已经成为很多实验的强制指标之一了。
下面我们详细讲一下R2值。
R2:R-square 我们也常称之为确定系数。
R2值的计算方法比较复杂,在这里只是简单的列出,不做详细解析。R2值由两个参数SSR和SST决定的。
(1)SSR:Sum of squares of the regression,即预测数据与原始数据均值之差的平方和,公式如下
(2)SST:Total sum of squares,即原始数据和均值之差的平方和,公式如下
SST=SSE+SSR,而我们的“确定系数”是定义为SSR和SST的比值,故
其实“确定系数”是通过数据的变化来表征一个拟合的好坏。由上面的表达式可以知道“确定系数”的正常取值范围为[0 1],越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的也较好。
通常来讲,R2值越大,曲线拟合越好。上图BCA蛋白检测的曲线拟合就非常吻合实验数据,说明我们的线性拟合类型是正确的。
示例2:
下图是细菌内毒素检测常见的样品排列方式:
左侧为样品排列方式和标准品EU值,右侧为每个孔对应的相应时间。
仪器测量一段时间内每个样品孔的变化趋势,软件会自动给出每个样品达到预设条件所需要的时间。
以标准品的EU值和每个标准品达到预设条件所需要的时间绘制标准曲线(自变量和因变量非直接相关)。
我们首先尝试做线性拟合,得到下图:
很明显,我们选择的曲线拟合类型有问题,不符合我们的实验。R2=0.387 也证明我们拟合类型有误。
根据前面的推论,我们选择对数拟合

得到下面的曲线:
很明显,细菌内毒素检测数数据符合Log(Y)=A*Log(X)+B拟合类型。R2=0.981 也符合我们实验R2>0.9的要求。
也许有人问了,为什么不再尝试其他更多项的曲线拟合呢,使用四参数会不会效果更好呢?
我们尝试使用四参数拟合,得到下图:
貌似拟合也不错,R2= 0.992 , 相比Log(Y)=A*Log(X)+B 的0.981 还要好一点,那么我们究竟是选择哪种拟合方式呢?
我们在确定拟合类型时一般遵循下面原则:
能使用简单的拟合方式,就尽量不使用复杂的拟合方式
首选最少参数的拟合方式
四参数或五参数拟合类型是最常见的两种非线性拟合方式,他们两个都适用S形曲线的拟合分析,虽然可以适合大多数的实验类型,但是他们有太多的使用限制:
至少需要4个点或5个点的数据
6个以上的数据点才能获得比较准确的拟合公式
综上所述:
四参数拟合方程Y = (A-D)/(1+(X/C)^B) + D的R2值虽然比Log(Y)=A*Log(X)+B的R2值大,但是他需要四个参数才能使曲线具有较多的拐点来适应匹配数据,Log(Y)=A*Log(X)+B只需要两个参数就可以很好的匹配数据了,我们的实验只有4个标准品,不适合选择四参数拟合,可以确认Log(Y)=A*Log(X)+B是最佳的拟合方式。
上面的两个示例都是线性回归,基本上使用R2值就可以判断拟合方式是否合适。比较简单。由于生物实验的复杂性,很多实验使用的都是非线性拟合,样品的标准偏差往往在不同的样品浓度下是不一样的,这些情况会导致R2值出现偏差而不准确。我们把标准偏差一样的数据成为同方差性,同方差是一种理想情况,通常情况下,标准偏差往往会随着样品浓度的增加而增加,这样的数据我们称为异方差性。
这里我们不对同方差和异方差进行详细解释,只简单说明一下:
最简单的示例就是一元线性回归,通过X-Y的散点图就可以看出是否存在明显的散点扩大,缩小和复杂型趋势,如果存在,说明随机误差项可能存在异方差。
下图给出了X-Y散点图的几种可能情况,若散点图随着X的增加,散点图分布的区域变宽、变窄或者出现偏离带状区域的复杂情况,则认为随机误差项可能出现了异方差。异方差产生的原因一般包括的因素是:未知的影响因素,残缺数据,数据测量误差,模型设定误差及变量内在随机性。
在我们平常的实验中,我们一般看到Y值的标准差随着X值的变化在增加、减少或严重偏离中心值,我们基本上就可以确定,该数据具有异方差性。
异方差的后果:
参数评估量非有效性,不再具有最小方差的性质
最小二乘法(OLS)不再适合评估参数
解释变量的显著性检验失效,T检验和F检验也失去意义
模型预测失效
针对异方差问题,也有大量的检验方法:残差图示检验法、等级相关检验法、Glejser检验等等,对于我们来讲,最简单的方法就是残差图示检验法。
残差图示检验法(Residual Plot)
图示检验法是一种定性分析,可以看残差与拟合值y’的散点图,也可以看残差与某个解释变量的散点图,这是一种直观的方法,缺点是不够严谨,只能用来初步判断异方差的存在与否。
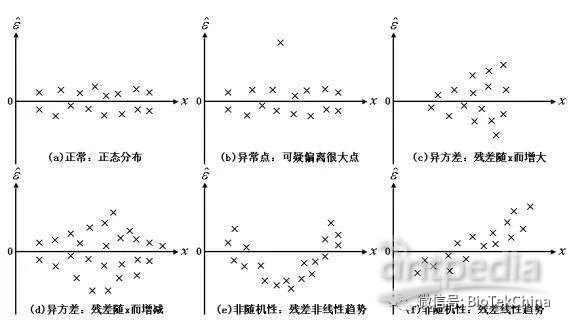
由于异方差性的存在与否不是我们判断的重点,我们不对其检验方法进行详细阐述。在这里我们主要是看,残差示意图中,残差是否正态分布在零点附近,如果分布在零点附件,就说明拟合方程对数据进行了很好的匹配。
如果出现异方差、非随机性分布,基本上我们是需要改变我们的拟合类型或者选择不同的加权因子来进行修正。
在异方差情况或残差示意图非随机分布的情况下,R2值就会出现偏差而不准确,除了需要考虑合适的权重因子外,还可以使用新的指标进行衡量: SSE(残差平方和)、F Probe、WSS(残差带权平方和)、 AIC(赤池信息量准则)、BIC(贝叶斯信息准则)等参数。
对于同方差性实验,由于所有样品的剂量标准偏差是相同的,在数据拟合时,不用考虑加权因子,直接选加权因子为无进行拟合。但是,对于异方差性实验,选择不同的加权因子,就变得非常有意义,正确的加权因子可以有效降低数据点和曲线之间的离散程度。
下面我们讲一下生物实验和药物筛选实验中经常使用的4P、5P非线性拟合方式。
如下图的一组数据:
下图是标准品在酶标板上的排列方式,使用BioTek 的Epoch2酶标仪检测达到的数据做曲线拟合。
我们先使用线性拟合回归看看
从图像上看,这是一个典型的S型曲线,使用直线拟合时数据点偏离曲线严重,虽然R-square 值大于0.9,但是我们并不能认为线性拟合是最佳的方式。
下面是使用4P拟合的结果:

很显然,4P曲线更适合本实验模型,所有的数据点都在曲线上,偏离极小。R-square等于0.999, 表面拟合程度非常好。
这里有两个数据 SSE、AIC,我们一直没有用到,下面我解释一下这两个数值的意义:
SSE:SSE(和方差、误差平方和,残差平方和):The sum of squares due to error,为了明确解释变量和随机误差各产生的效应是多少,统计学上把数据点与它在回归直线上相应位置的差异称为残差,把每个残差平方之后加起来 称为残差平方和,它表示随机误差的效应。一组数据的残差平方和越小,其拟合程度越好。
残差平方和SSE的计算方法如下:
表示预测值
表示拟合值
可以看出SSE是预测值和拟合值之间差异的平方和,这个数据越接近于零,说明预测值和拟合值越一致,拟合方程越匹配数据模型。SSE没有最大值限制,可以是几十、几百甚至上百万,它和样品量,预测值等多个因素相关。
AIC:Akaike information criterion、赤池信息量准则 ,简称AIC,是衡量统计模型拟合优良性的一种标准,是由日本统计学家赤池弘次创立和发展的。赤池信息量准则建立在熵的概念基础上,可以权衡所估计模型的复杂度和此模型拟合数据的优良性。
在一般的情况下,AIC可以表示为:
AIC=(2k-2L)/n
具体到,L=-(n/2)*ln(2*pi)-(n/2)*ln(sse/n)-n/2.其中n为样本量,sse为残差平方和
AIC=n*log(SSE/n)+2K
它的假设条件是模型的误差服从独立正态分布。
其中:k是所拟合模型中参数的数量,L是对数似然值,n是样本量。
AIC的大小取决于L和k。k取值越小,AIC越小;L取值越大,AIC值越小。k小意味着模型简洁,L大意味着模型精确。因此AIC和修正的决定系数类似,在评价模型是兼顾了简洁性和精确性。
AIC鼓励数据拟合的优良性但是尽量避免出现过度拟合(Overfitting)的情况。所以优先考虑的模型应是AIC值最小的那一个。赤池信息准则的方法是寻找可以最好地解释数据但包含最少自由参数的模型。
其他参数如:BIC、WSS不做详细的解释。
BIC(Bayesian InformationCriterion)贝叶斯信息准则与AIC相似,用于模型选择,1978年由Schwarz提出。训练模型时,增加参数数量,也就是增加模型复杂度,会增大似然函数,但是也会导致过拟合现象,针对该问题,AIC和BIC均引入了与模型参数个数相关的惩罚项,BIC的惩罚项比AIC的大,考虑了样本数量,样本数量过多时,可有效防止模型精度过高造成的模型复杂度过高。
WSS是残差带权平方和,与SSE的作用相似。
结论:
在曲线拟合类型的选择上没有绝对的标准,下面几点可以作为参考:
拟合方程的参数越少越好,最少的参数达到最佳的拟合效果
R-square 值:在0~1之间,越接近于1越好,越接近1说明拟合方程越匹配数据
SSE 值:越接近于零越好,SSE为零时,表示最匹配数据
AIC值:越小越好,其实就是第一条,拟合参数最少原则
同方差性数据不必使用加权因子
异方差数据可以设置合适的加权因子,让SSE更小


















 首页
首页




