Molecule in this Month(2019.11)
这个月的解析案例有点特殊,案例是一个合成副产物,来自于柏林Leibniz-Forschungsinstitut fürMolekulare Pharmakologie (FMP)公司,Dr.Marc Nazaré实验室。Dr.Peter Schmieder用这组数据来挑战ACD/Labs SES的能力,Dr. Rana Alsalim,Dr. Peter Lindemann 和Dr. Edgar Specker也参与了这次的挑战。
样品来源是合成反应分离后的产物,由高分辨质谱得知分子式为C14H13N3O。虽然这是一个分子量相对较小的化合物,但还是一个比较有意思的案例。
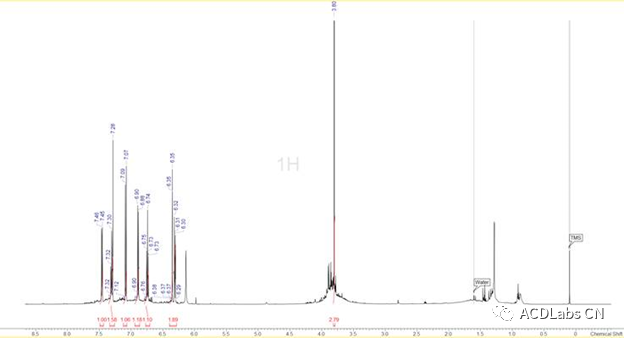
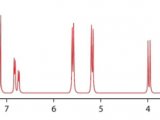
图1:化合物的H谱,结合分析HMQC得到的标峰积分结果。
谱图显示样品纯度不是很好,H谱如图1所示,除了芳环区较容易辨认的峰外,谱图在3.8ppm左右有一组宽峰,在2.5ppm有些比较小的峰。还有一些比较好辨认的杂质峰,如0.8ppm,1.9ppm的一些峰很大可能是来源于瓶子接口处的油脂,其余的峰相对比较难以辨认均为未知杂质峰。有意思的是,所有的峰的底部都有一个宽峰,这表面样品中含有一系列结构类似的杂质。TMS的峰形较好,这一点可以排除仪器参数设定不正确的可能性(如,高阶匀场不好)。

图2:化合物的C谱,标峰处理了比较高的14个峰
幸运的是C谱图(图2)信号较佳,只有一些细小的杂信号且强度跟样品信号比低很多。C谱图存在14个信号,跟化学式C的个数吻合。可以以这个为基础分析其他谱图中的有效信号。
在解析前,检索数据库看看在存不存在类似C谱的已知化合物是一个比较有必要的过程,这就是C谱排重。如果存在已知化合物的C谱跟实验谱图相似,就可以避免重复的解析过程,再次从头解析一个存在的已知化合物结构的谱图显得没有任何意义。ACD/SES已知化合物数据库(known compounds)为9800W个化合物预测C谱图数据库, 结构信息来源于Pubchem,数据库可以使用C谱峰(1D,2D HSQC HMBC里的C信号)进行检索,同时检索时可以综合化合物的分子量信息,化学式。
令人惊讶的是化合物库的检索结果没有发现跟给定化合物的C谱很相似的结构。如果检索时检索条件较苛刻(即认为所有C峰都是信号没有杂信号,没有丢失或多余的信号),则没有任何命中结构。如果谱峰个数标准放松允许丢失或多余C信号,则命中一些结构式,但这些都不是化合物结构式。图3是一些检索结果,从检索结果中唯一可以确认的是该化合物至少存在两个芳环。这就有些意外了,一般认为比较小的结构都是已知结构化合物,但这个例子显然不是,所以接下来就只有从头解析了。

图3.软件检索到类似C谱的化合物结构,检索条件放松到允许存在最多2个丢失或多余C信号。即使这些结构明显不正确(左边结构存在两个甲基,右边结构存在亚甲基而没有甲基),但结果表明化合物结构中可能存在两个芳环和一个氰基基团。
接下来就是分析H-C HMQC的谱图(图4).由于已经知道C谱的有效信号,所以只要集中注意这些C的相关信号即可,这样就可以有效避免发生信号辨认错误的情况。从HMQC的谱图中可以分析出8个跟H谱有相关的信号,其中7个为芳环区的H,均为CH,3.8ppm处的单峰结合积分面积分析出该信号为CH3.

图4:H-C HMQC谱图
使用同样方法分析H-CHMBC谱图(图5),只标出H和C有效信号合理的相关点。该样品的谱图中有些容易标识错误的信号点,如HMBC谱图中比较常见H-C一键相关信号,还有一些杂质的信号。ACD软件内建算法能自动分析出一键相关信号,在标峰时可以自动剔除这些一键信号。通常的策略就是只标识确定的信号而避免不确定的信号。

图5 H C HMBC谱图
从样品的COSY的谱图(未展示)可以识别出芳环H的连接情况,进而有效确认结构中存在两个芳环的想法。ACD/SES软件自动分析出所有谱图的信号列表如表1所示。

图6软件自动生成的MCD图,文中提及的编辑修改过杂化信息的C,在MCD图中用下标线做标记。
C原子的杂化信息由软件自动生成。只有3处经过编辑修改, C12(144.94ppm),C13(149.29ppm)和C14(153.98ppm)改为SP2杂化。浅蓝色的两个C原子(C3 99.4 ppm 和 C4 106.79 ppm)表示这两个C不是SP杂化形式。3个黑色的C (C2 97.06 ppm, C7 117.97 ppm 和C8 119.57 ppm)表示他们的杂化形式未知。C1, 55.51 ppm有ob标记表示该C原子至少跟一个杂原子相邻。HMBC的相关信号根据其信号强弱标记为绿色(2-3键)和紫红色(4键)。这些均由软件自动生成。
软件检查MCD图后发现只一个警告信息,分子式的H比谱图中识别出H的个数多。这通常表明结构中存在活泼H(如OH,NH基团),即使这些信号不可见,对ACD/SE来说也不是问题。MCD检测通过后,生成结构时采用一般模式,同时勾选了允许杂原子直接相邻,甚至时同种杂原子相邻的选项,这是因为反应物中存在重氮基团。生成结果: k = 660474 → (内部筛选) → 10 → (去除重复) → 7, tg= 13m 15s.
接下来根据实验C谱图与预测C谱图的C平均偏差对生成的结构进行排序。在之前的每月解析案例中,我们预测C谱时均采用的HOSE算法,这次我们使用了HOSE和NN神经网络两种算法。C谱图偏差从小到大排列后,图7显示的是C谱偏差最小的前三个结构。

图7:生成偏差最小的前三个结构
我们可以看到第一个第二个结构的C平均偏差都比较小。神经网络算法第一个结构偏差dN(13C)为2.743ppm,第二个结构的偏差为2.771ppm。HOSE算法的第一个结构的平均偏差dA(13C)为2.901,第二个结构的偏差为2.669ppm。神经网路算法显示第一个结构较佳,而HOSE算法显示第二个结构较佳。通常平均偏差低于3.5ppm的结构都能接受,所以两个结构似乎都是合理的。两个结构的平均偏差都比较小,所以很难决定哪个是正确结构。事实上,两种算法给出完全相反的结论,就说明在排序时就有很大不确定型。这是一个意外的合成产物,结合合成反应判定第一个结构为正确结构的做法就可能有一定的危险性。
以前我们有使用过DFT算法计算化学位移排除不确定性找出正确结构的案例,但DFT算法对一些官能团也有一定的局限性,所以采集更多的谱图来解决这样的问题更为简单。由于化学式中含有N,所以就增加了H-N HMBC实验。谱图如图8所示。

图8: H-N HMBC谱图
很明显,三个N中只有两个N采集出了信号,ACD/SE可以解决类似这样一些原子没有2D相关信号的问题。图4的MCD图中显示我们有3个N原子,从二维谱图H-N HMBC中也可以看到大部分的信号都是跟确定的H有相关信号,只有一个N位移79ppm存在两个信号虽然不与H直接相关,但与一个宽的H信号中心对称6.14ppm。这个两个信号为残留的N-H一键相关信号,信号在6.14ppm宽峰附近这表明我们的结构中含有NH基团。
除了在6.36ppm 79.08ppm的一处信号较弱外,其余的的信号强度均一致。这一个弱信号为4键相关信号,其余均为2-3键相关信号。更新后的MCD图如图9所示。我们可以看到有两个N与C存在相关。

图9:增加H N HMBC谱图后软件生成的MCD
使用一般模式生成结构列表k = 1800 → (内部筛选)→ 2 → (去除重复结构)→ 2, tg = 17s. 生成的两个结构如图10所示。

图10,增加H-N HMBC数据后生成的结构
现在我们可以看到先前生成的两个结构中只有一个结构再次出现,先前结构不确定性的问题不再存在。现在可以明显看到第二个结构相对第一个结构来讲化学位移平均偏差都比较大。毫无疑问第一个结构为正确结构。生成结构的过程中,计算速度有明显提升,46倍。
解析出的结构也FMP公司人工解析的结果一致。图11为信号归属后的化学结构。
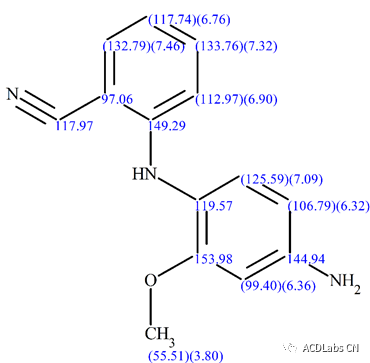
图11 合成产物的最终结构,结构上表示出 H C N 的化学位移
以上解析过程表明增加NMR谱图不仅可以消除不确定性而且可以减少分析时间。DFT计算化学位移似乎可以解决类型这种结构无法确定的问题,但是有些时候增加NMR谱图就可以达到同样的效果。对现在的NMR谱仪来说H-N HMBC谱图很容就就可以采集,这类实验并不再是只对NMR专家特殊用途开发的。
References:
1 ACD/Labs Structure Elucidation Challenge
2 A. V. Buevich, M. E. Elyashberg. (2016). Synergistic combination of CASE algorithms and DFT chemical shift predictions: a powerful approach for structure elucidation, verification and revision. J. Nat. Prod., 79 (12):3105–3116.
3 A.V. Buevich, M. E. Elyashberg. (2018). Towards unbiased and more versatile NMR-based structure elucidation: A powerful combination of CASE algorithms and DFT calculations. Magn. Reson. Chem., 56: 493–504. DOI: 10.1002/mrc.4645















 首页
首页




